


Need smarter insights in your inbox? Join our weekly newsletters to get solely what issues to enterprise AI, information, and safety leaders. Subscribe Now
Mistral launched an open-sourced voice mannequin at this time that might rival paid voice AI, comparable to these from ElevenLabs and Hume AI, which the corporate mentioned bridges the hole between proprietary speech recognition fashions and the extra open, but error-prone variations.
Voxtral, which Mistral will launch underneath an Apache 2.0 license, is accessible in a 24B parameter model and a 3B variant. The bigger mannequin is meant for functions at scale, whereas the smaller model would work for native and edge use circumstances.
“Voice was humanity’s first interface—lengthy earlier than writing or typing, it allow us to share concepts, coordinate work, and construct relationships. As digital methods develop into extra succesful, voice is returning as our most pure type of human-computer interplay,” Mistral mentioned in a weblog put up. “But at this time’s methods stay restricted—unreliable, proprietary, and too brittle for real-world use. Closing this hole calls for instruments with distinctive transcription, deep understanding, multilingual fluency, and open, versatile deployment.”
Voxtral is accessible on Mistral’s API and a transcription-only endpoint on its web site. The fashions are additionally accessible by means of Le Chat, Mistral’s chat platform.
The AI Affect Collection Returns to San Francisco – August 5
The following part of AI is right here – are you prepared? Be part of leaders from Block, GSK, and SAP for an unique take a look at how autonomous brokers are reshaping enterprise workflows – from real-time decision-making to end-to-end automation.
Safe your spot now – house is restricted: https://bit.ly/3GuuPLF
Mistral mentioned that speech AI “meant selecting between two trade-offs,” stating that some open-source automated speech recognition fashions usually had restricted semantic understanding. Nonetheless, closed fashions with robust language understanding come at a excessive value.
Bridging the hole
The corporate mentioned Voxtral “gives state-of-the-art accuracy and native semantic understanding within the open, at lower than half the value of comparable APIs.”
Voxtral, at a 32K token context, can take heed to and transcribe as much as half-hour of audio or 40 minutes of audio understanding. It gives summarization, that means the mannequin can reply questions primarily based on the audio content material and generate summaries with out switching to a separate mode. Customers can set off features and API calls primarily based on spoken directions.
The mannequin relies on Mistral’s Mistral Small 3.1. It helps a number of languages and might routinely detect languages comparable to English, Spanish, French, Portuguese, Hindi, German, Italian, and Dutch.
Mistral added enterprise options to Voxtral, together with personal deployment, in order that organizations can combine the mannequin into their very own ecosystems. These options additionally embrace domain-specific fine-tuning and superior context and precedence entry to engineering assets for purchasers who need assistance integrating Voxtral into their workflows.
Efficiency
Speech recognition AI is now out there on many platforms at this time. Customers can communicate to ChatGPT, and the platform will course of spoken directions equally to written prompts. Quick meals chains like White Fort have deployed SoundHound to their drive-thru providers, and ElevenLabs has steadily been bettering its multimodal platform. The open-source house additionally gives highly effective choices. Nari Labs, a startup, launched the open-source speech mannequin Dia in April. Nonetheless, a few of these providers might be fairly costly.
Transcription providers like Otter and Learn.ai can now embed themselves into Zoom conferences, recording, summarizing and even alerting customers to actionable objects. Many on-line video assembly platforms supply not simply transcription, but additionally speech AI and agentic AI, with Google Conferences offering the choice to take notes for customers utilizing Gemini. As an everyday person of voice transcription providers, I can say firsthand that speech recognition AI will not be excellent, however it’s bettering.
Mistral said that Voxtral outperformed current voice fashions, together with OpenAI’s Whisper, Gemini 2.5 Flash and Scribe from ElevenLabs. Voxtral offered fewer phrase errors in comparison with Whisper, which is at present thought-about the perfect computerized speech recognition mannequin out there.
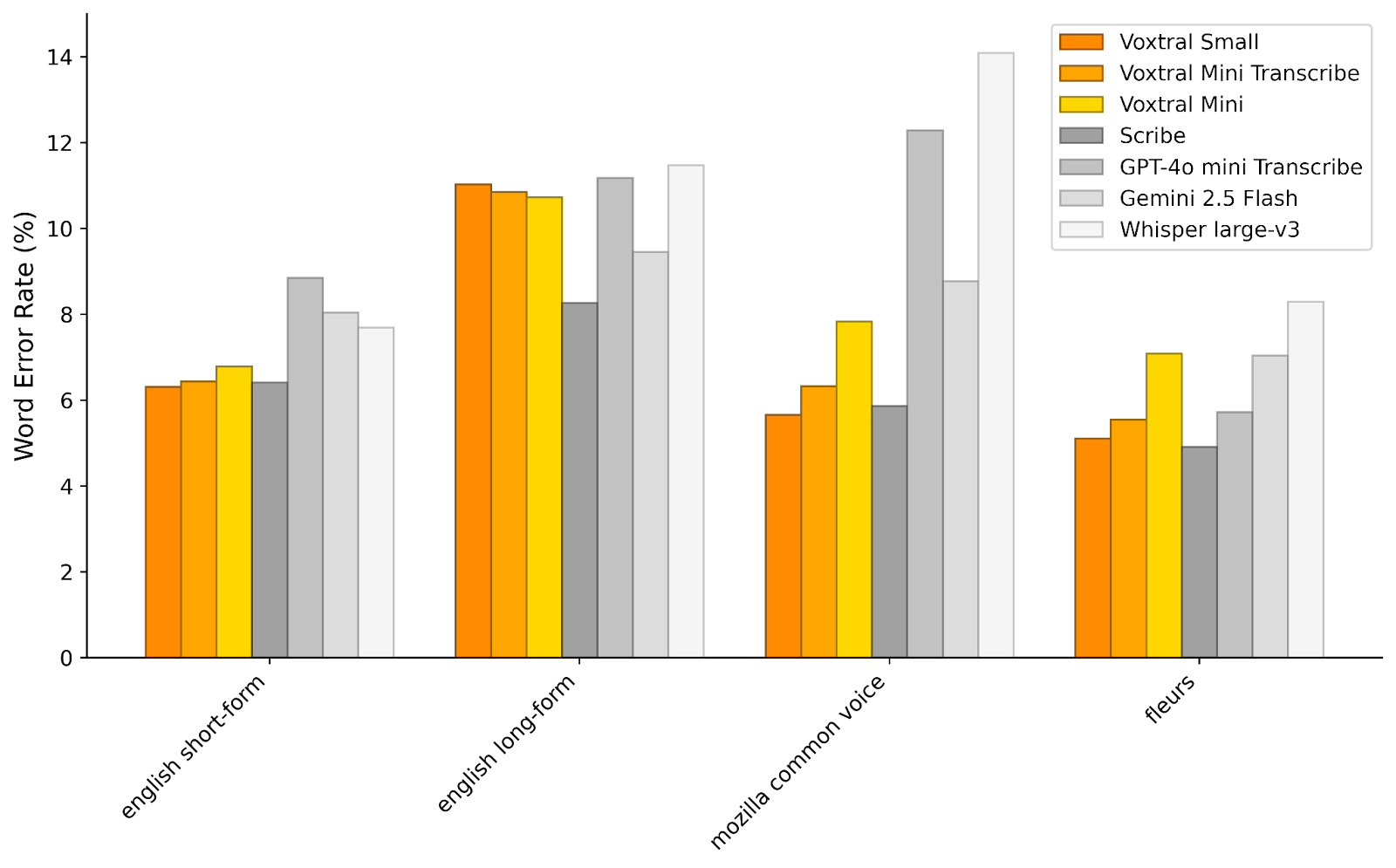
By way of audio understanding, Voxtral Small is “aggressive with GPT-4o-mini and Gemini 2.5 Flash throughout all duties, reaching state-of-the-art efficiency in Speech Translation.”
Since saying Voxtral, social media customers mentioned they’ve been ready for an open-source speech mannequin that may match the efficiency of Whisper.
Mistral mentioned Voxtral will probably be out there by means of its API at $0.001 per minute.








